
Milyen világot teremtünk magunknak a mesterséges intelligenciával? Ez a jövő legfontosabb kérdése.

A Corvinus Fintech Center márciusban indult előadás-sorozata a mesterséges intelligencia és a gépi tanulás témáit mutatja be az érdeklődő közönségnek. A sorozat nyitóalkalmán vendégelőadóként Bárd Imre, a London School of Economics doktorjelöltje beszélt a mesterséges intelligencia szabályozásának jövőjéről. A szeminárium-sorozatot egyetemünk stratégiai igazgatója, Barta Márton nyitotta meg, a témát Dr. Trinh Anh Tuan, a Corvinus Fintech Center vezetője, a sorozat házigazdája vezette fel.
Áldás vagy átok a mesterséges intelligencia (MI)? Minden eddiginél nagyobb szabadságot és jólétet, vagy minden eddiginél nagyobb elnyomást és egyenlőtlenséget teremt majd az emberiség számára? Ezeket a kérdéseket aligha tudjuk megválaszolni anélkül, hogy tudnánk, hogyan érintik majd a fejlett technológia adta lehetőségek meglévő társadalmi rendszereinket. Mit kell átalakítanunk? Mit kell szabályoznunk? Kinek milyen jogai és kötelezettségei lesznek korábban sosemvolt helyzetekben? Bárd Imre, a London School of Economics doktorjelöltje a mesterséges intelligencia governance kérdéseiről beszélt március 1-jei előadásán.
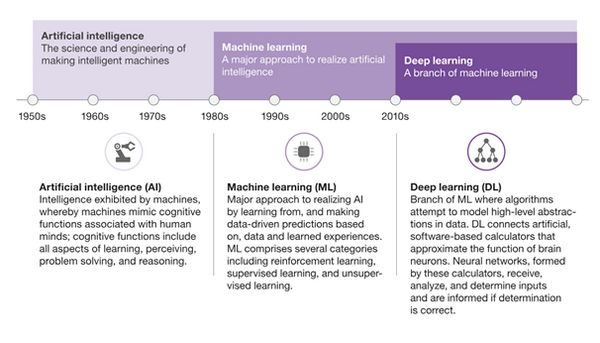
A „mesterséges intelligencia” kifejezést John McCarthy alkotta meg 1956-ban, de mindenki által elfogadott definíciót azóta sem sikerült hozzá találni. (Legtágabb értelemben olyan technológiát érthetünk alatta, amely emberi módon, illetve racionálisan képes gondolkodni vagy cselekedni.) Még ha a pontos meghatározással egyelőre adós is a tudomány, az MI definiálására tett kísérletek sokkal közelebb vittek minket az intelligencia jelentésének megértéséhez. Érdekes összefüggésre világít rá például az úgynevezett MI-paradoxon: ha egy problémát már megoldottunk, akkor annak újbóli megoldásához már nincs szükség valódi intelligenciára.
Bárd Imre előadásában bemutatta az MI két típusát: az általános MI-t, amely a rugalmas és alkalmazkodóképes intelligencia teljes spektrumával rendelkezik; illetve a specifikus MI-t, amely egy-egy jól definiált probléma megoldására alkalmas. A leginkább előremutató technológia talán mégis a neuronhálózatok alkalmazásán alapuló úgynevezett „mélytanulás” (deep learning). A mélytanulás a gépi tanulás egy ágazata, melynek lényege, hogy sok ezer vagy akár sok millió adatpont bevitelével bizonyos mintázatok felismerésére tanítjuk meg a mesterséges intelligenciát, amelyeket az később magától is képes lesz felismerni. Az algoritmusok megpróbálják megtanulni az adatokban rejlő magas szintű absztrakciókat (mely pl. a neurális hálózatoknál több belső/hierarchikus réteget jelent). Ez a betanítási folyamat sokféleképpen történhet, a legfontosabb tényező azonban minden esetben az input minősége. Megfelelő adatokat kell használnunk ahhoz, hogy jó mintázatok felismerésére tanítsuk meg az MI-t.
Az MI technológiához kapcsolódóan sok zavarba ejtő hírt olvashattunk az elmúlt években. A Cambridge Analytica több millió Facebook-felhasználó adatait szerezte meg beleegyezésük nélkül, majd az adatokat az amerikai választások kimenetének befolyásolására használták fel. Az IBM Watson téves kezeléseket javasolt rákos betegeknek. Stanfordi kutatók olyan algoritmust fejlesztettek ki, amely fényképek alapján megközelítő pontossággal képes megállapítani egy ember szexuális orientációját. Egyes döntéstámogató MI-kről kiderült, hogy rasszista előítéleteik vannak. A sort még hosszan folytathatnánk.
A fenti példák mindegyike olyan helyzeteket mutatott be, amelyekben súlyos problémákat vetett fel a mesterséges intelligencia alkalmazása. Bárd Imre szerint az ilyen helyzetek elkerülésének érdekében van szükség az MI társadalmi szabályozására, illetve a tisztességesség, a transzparencia és az elszámoltathatóság alapelveinek betartására.
Ahogy az emberi döntéseknél is komoly problémát jelentenek a különböző észlelési torzítások, a mesterséges intelligencia esetében is kialakulhatnak ilyenek. Mivel gépi tanulás esetén a felhasznált adatok alapján alakulnak ki a döntési mechanizmusok, létfontosságú, hogy jó minőségű adatokat tápláljunk be a rendszerbe. Biztosítani kell például, hogy az adatok reprezentatívak az alapsokaságra nézve, és hogy nem tartalmaznak rejtett emberi előítéleteket. A mesterséges intelligencia ilyen értelemben nem más, mint az emberi gondolkodás és társadalom tükre: a döntéseiben megjelenő sztereotípiákat önkéntelenül is mi tanítjuk meg neki.
A transzparencia elve kettős célt szolgál az MI-vel kapcsolatos szabályozásokban. Egyrészt biztosíthatja, hogy meg is értsük, mi alapján döntött az MI. Másrészt hozzájárulhat ahhoz, hogy ne alakulhassanak ki olyan adatgyűjtő és adatfeldolgozó monopóliumok, amelyek végzetesen veszélyeztetnék az emberi szabadságot és az önálló döntéseinket.
A jelenleg elérhető mesterséges intelligenciák az előre megtanult mechanizmusok alapján ugyan döntéseket tudnak hozni, de döntéseik okát egyelőre nem képesek emberek számára is érthető módon elmagyarázni. Ahhoz, hogy komoly, akár emberek sorsát is érintő döntéseket bízzunk rájuk, meg kell tudnunk érteni ezek logikai alapjait. Egyes fejlesztők ezért olyan MI-ken dolgoznak, amelyek már magyarázó modellt is tudnak készíteni saját döntési mechanizmusaikhoz – ezek azonban jelen pillanatban nem állnak készen.
A túl sok adat és hatalmas adatfeldolgozó kapacitás az „átlátszó emberek” rémképével fenyeget. Ahogy Yuval Noah Harari írja, az emberek maguk is “meghekkelhetővé” válhatnak. Ha egyes államok vagy nagyvállalatok képesek lesznek kellően nagy mennyiségű adatot gyűjteni személyünkről, az ezekből kiolvasható összefüggések és mintázatok alapján olyan dolgokat is megtudhatnak rólunk, amiket esetleg mi magunk sem ismerünk. Ezen tudás birtokában pedig könnyedén manipulálhatják döntéseinket. Bárd Imre szerint az EU GDPR szabályozása azért előremutató, mert az átlagemberek figyelmét is felhívja arra, hogy a személyes adataik értékesek, és mindenkinek joga van tudni, ki, hogyan és miért kezeli ezeket.
Az MI-szabályozás egyik legérzékenyebb pontja talán az elszámoltathatóság kérdése. Kit terhel a felelősség az MI által okozott esetleges károkért? Ki kényszeríthető ezek helyrehozatalára? Ezek a kérdések nem csupán jogi szempontból érdekesek. A jogszabályok csak tökéletlenül tudják modellezni társadalmi értékeinket, ezeknek a kérdéseknek a megválaszolása ezért legalább felerészben morális és értékválasztási feladat.
Az MI hozta változások természetesen a munkaerőpiacon is éreztetik hatásukat. Várhatóan folytatódnak majd a jelenlegi trendek: a gépek és a szoftverrobotok egyre több munkahelyet vesznek át az emberektől. Ez komoly társadalmi feszültségeket eredményezhet, amelyek kezelésére fel kell készülnünk. A munkaerőpiaci változások ugyanakkor lehetővé és egyben szükségessé is teszik, hogy megkérdőjelezzük néhány előfeltevésünket, és újragondoljuk a munka társadalmi szerepét, vagy a javak elosztásának alapelveit.
Látható, hogy az MI teremtette új helyzetek szabályozása kulcsfontosságú: erre a „kemény” törvényi szabályoktól kezdve a „puhább” iparági szabványokig vagy önként vállalt céges előírásokig sok lehetőség kínálkozik. A fejlesztőknek és a jogalkotóknak közösen kell készülniük az új helyzetekre, ami sok próbálkozást igényel. Jó kezdeményezésnek tűnnek azok a törvényi „homokozók”, amelyek védett környezetet jelentenek a fejlesztők és a jogalkotók számára egyaránt – amíg közösen létre nem hozzák a működő társadalmi és technológiai megoldásokat.
Bárd Imre szerint az MI governance valójában nem is elsősorban a mesterséges intelligencia szabályozásáról szól, mint inkább egy olyan világ szabályozásáról, amiben mindenütt jelen van a mesterséges intelligencia. Ki kell találnunk, milyen világot akarunk teremteni általa – ez a jövő legfontosabb kérdése.
(A Corvinus Fintech Center előadás-sorozata folytatódik.)
Baksa Máté